Mike He

I am a Ph.D. student at the Princeton Programming Languages Group advised by Prof. Aarti Gupta. I am broadly interested in programming languages, formal methods and compilers. My current research focuses on practical formal and semi-formal methods for distributed systems and agentic systems, and I am working with the P ecosystem for verifying and reasoning about distributed systems.
Before joining Princeton, I studied at the University of Washington, where I was privileged to work with Prof. Zachary Tatlock on equality saturation and its applications to machine learning compilers.
In my free time, I enjoy playing the violin (I've been playing it longer than coding). You can find my archived recordings here.
CV Twitter Scholar Github LinkedIn

- 2022: CRA Outstanding Undergraduate Researcher Award, Honorable Mention
- 2020: Lynn Conway Research Award (DTR Team)
- 2019: JASSO Scholarship, Waseda University
- 2018 → 2022: Annual Dean's List, University of Washington
- 2016: NOIp 2nd Prize, Beijing Regional
Conference / Journal Publications & Pre-prints
(*: Core contributor)
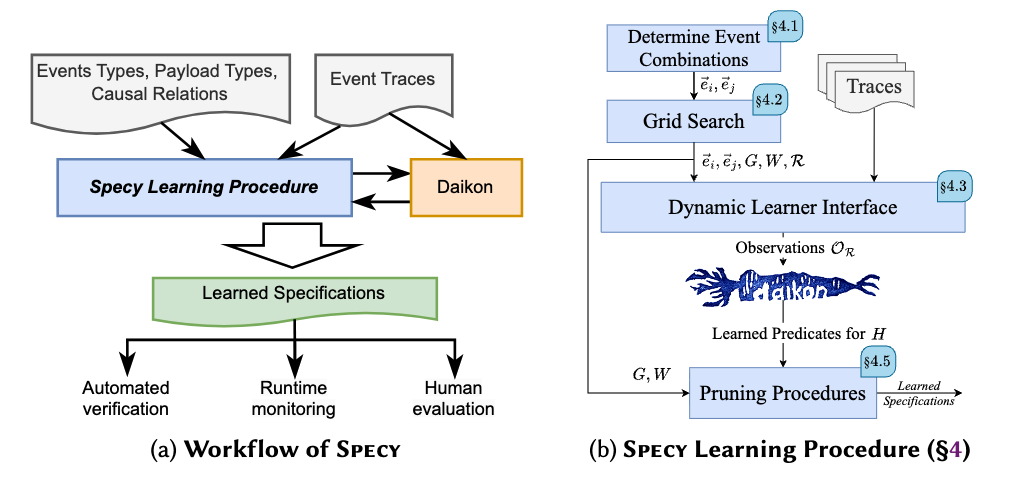
Mike He, Ankush Desai, Aishwarya Jagarapu, Doug Terry, Sharad Malik, Aarti Gupta
Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA), 2026
PaperCode
@inproceedings{he2026specy,
author = "He, Mike and Desai, Ankush and Jagarapu, Aishwarya and Terry, Doug and Malik, Sharad and Gupta, Aarti",
title = "Specy : Learning Specifications for Distributed Systems from Event Traces",
booktitle = "Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA)",
year = "2026",
url = "https://2026.splashcon.org/details/oopsla-2026/10/Specy-Learning-Specifications-for-Distributed-Systems-from-Event-Traces"
}
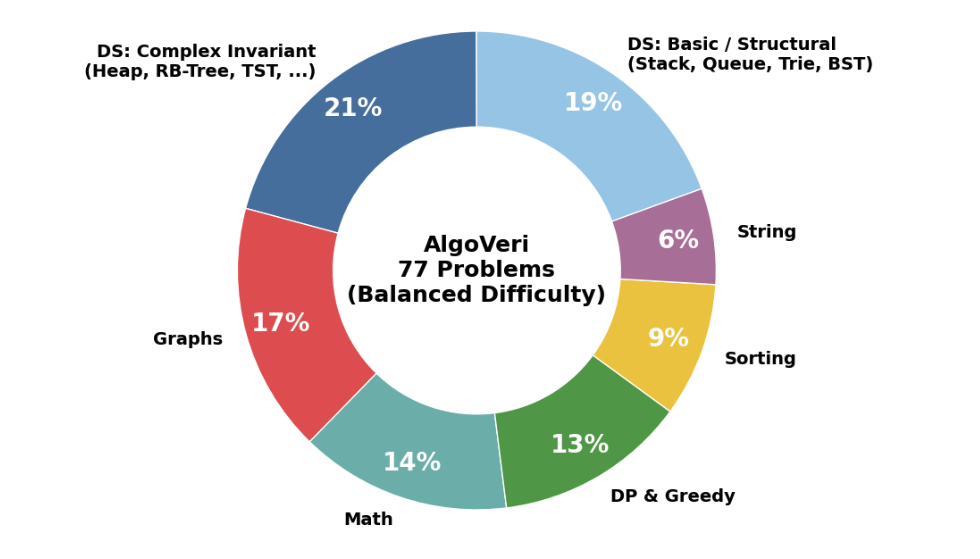
Haoyu Zhao*, Ziran Yang*, Jiawei Li*, Deyuan He*, Zenan Li*, Chi Jin, Venugopal V. Veeravalli, Aarti Gupta, Sanjeev Arora
International Conference on Machine Learning (ICML), 2026
PaperCode
@article{zhao2026algoveri,
author = "Zhao*, Haoyu and Yang*, Ziran and Li*, Jiawei and He*, Deyuan and Zenan Li* and Jin, Chi and Veeravalli, Venugopal V. and Gupta, Aarti and Arora, Sanjeev",
title = "AlgoVeri: An Aligned Benchmark for Verified Code Generation on Classical Algorithms",
booktitle = "International Conference on Machine Learning (ICML)",
year = "2026",
url = "https://www.arxiv.org/abs/2602.09464"
}
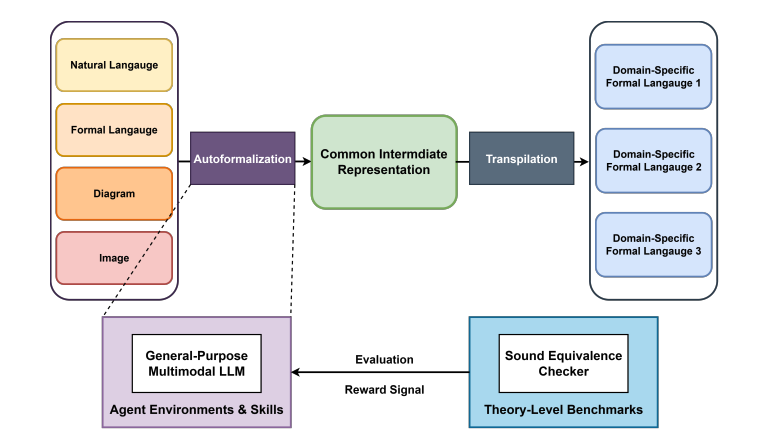
Marcus Min, Mike He, Zhaoyu Li, Zixuan Yi, Sharad Malik, Aarti Gupta, Xujie Si, Osbert Bastani
International Conference on Machine Learning (ICML), Position Track, 2026
Paper
@misc{min2026tla,
author = "Min, Marcus and He, Mike and Li, Zhaoyu and Yi, Zixuan and Malik, Sharad and Gupta, Aarti and Si, Xujie and Bastani, Osbert",
title = "Theory-Level Autoformalization: From Isolated Statements to Unified Formal Knowledge Bases",
year = "2026",
booktitle = "International Conference on Machine Learning (ICML), Position Track",
url = "https://papers.ssrn.com/sol3/papers.cfm?abstract\_id=6922158"
}

Zenan Li*, Ziran Yang*, Deyuan He, Haoyu Zhao, Andrew Zhao, Shange Tang, Kaiyu Yang, Aarti Gupta, Zhendong Su, Chi Jin
Conference on Language Modeling (COLM), 2026
Project PagePaperCode
@misc{li2026goedelcodeproverhierarchicalproofsearch,
author = "Li*, Zenan and Yang*, Ziran and He, Deyuan and Zhao, Haoyu and Zhao, Andrew and Tang, Shange and Yang, Kaiyu and Gupta, Aarti and Su, Zhendong and Jin, Chi",
title = "Göedel-Code-Prover: Hierarchical Proof Search for Open State-of-the-Art Code Verification",
year = "2026",
eprint = "2603.19329",
archivePrefix = "arXiv",
primaryClass = "cs.SE",
booktitle = "Conference on Language Modeling (COLM)",
url = "https://arxiv.org/abs/2603.19329"
}
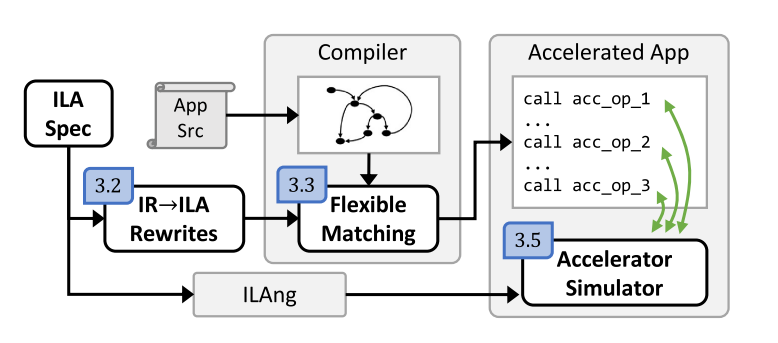
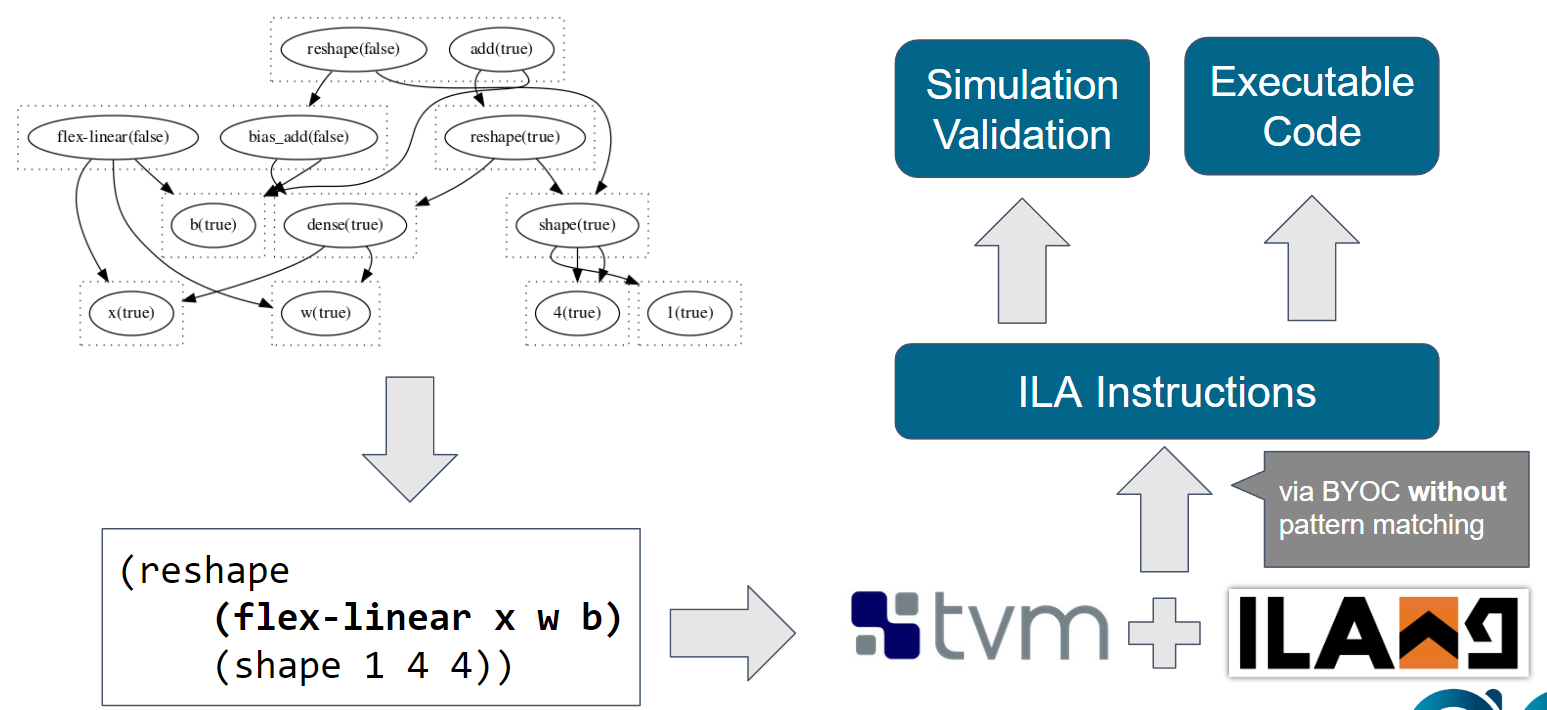
Bo-Yuan Huang, Steven Lyubomirsky, Yi Li, Mike He, Gus Henry Smith, Thierry Tambe, Akash Gaonkar, Vishal Canumalla, Andrew Cheung, Gu-Yeon Wei, Aarti Gupta, Zachary Tatlock, Sharad Malik
ACM Trans. Des. Autom. Electron. Syst. (TODAES), 2024
Project PagePaper
@article{huang233la,
author = "Huang, Bo-Yuan and Lyubomirsky, Steven and Li, Yi and He, Mike and Smith, Gus Henry and Tambe, Thierry and Gaonkar, Akash and Canumalla, Vishal and Cheung, Andrew and Wei, Gu-Yeon and Gupta, Aarti and Tatlock, Zachary and Malik, Sharad",
title = "Application-level Validation of Accelerator Designs Using a Formal Software/Hardware Interface",
year = "2024",
issue_date = "March 2024",
publisher = "Association for Computing Machinery",
address = "New York, NY, USA",
volume = "29",
number = "2",
issn = "1084-4309",
url = "https://doi.org/10.1145/3639051",
doi = "10.1145/3639051",
abstract = "Ideally, accelerator development should be as easy as software development. Several recent design languages/tools are working toward this goal, but actually testing early designs on real applications end-to-end remains prohibitively difficult due to the costs of building specialized compiler and simulator support. We propose a new first-in-class, mostly automated methodology termed “3LA” to enable end-to-end testing of prototype accelerator designs on unmodified source applications. A key contribution of 3LA is the use of a formal software/hardware interface that specifies an accelerator’s operations and their semantics. Specifically, we leverage the Instruction-level Abstraction (ILA) formal specification for accelerators that has been successfully used thus far for accelerator implementation verification. We show how the ILA for accelerators serves as a software/hardware interface, similar to the Instruction Set Architecture for processors, that can be used for automated development of compilers and instruction-level simulators. Another key contribution of this work is to show how ILA-based accelerator semantics enables extending recent work on equality saturation to auto-generate basic compiler support for prototype accelerators in a technique we term “flexible matching.” By combining flexible matching with simulators auto-generated from ILA specifications, our approach enables end-to-end evaluation with modest engineering effort. We detail several case studies of 3LA, which uncovered an unknown flaw in a recently published accelerator and facilitated its fix.",
journal = "ACM Trans. Des. Autom. Electron. Syst. (TODAES)",
month = "February",
articleno = "35",
numpages = "25",
keywords = "Accelerator, domain-specific language, compilation, validation, software/hardware interface"
}
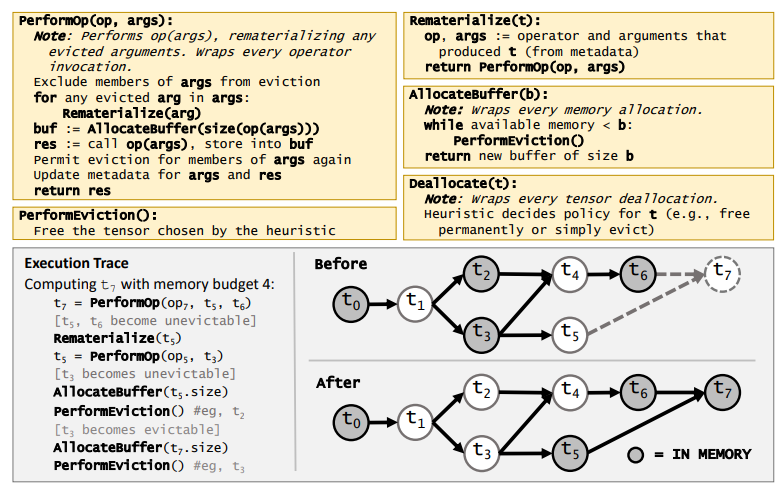
Marisa Kirisame*, Steven Lyubomirsky*, Altan Haan*, Jennifer Brennan, Mike He, Jared Roesch, Tianqi Chen, Zachary Tatlock
International Conference on Learning Representations (ICLR), 2021
Project PagePaperCode
@inproceedings{kirisame2021dynamic,
author = "Kirisame*, Marisa and Lyubomirsky*, Steven and Haan*, Altan and Brennan, Jennifer and He, Mike and Roesch, Jared and Chen, Tianqi and Tatlock, Zachary",
title = "Dynamic Tensor Rematerialization",
booktitle = "International Conference on Learning Representations (ICLR)",
year = "2021",
url = "https://openreview.net/forum?id=Vfs\_2RnOD0H"
}
Misc. Projects & Short Papers
(*: Core contributor)

Center for AI Safety, Scale AI, HLE Contributors Consortium
Nature, 2026
Project PagePaperCode
@article{hle2026,
author = "for AI Safety, Center and AI, Scale and Consortium, HLE Contributors",
abstract = "Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve more than 90{\\%} accuracy on popular benchmarks such as Measuring Massive Multitask Language Understanding1, limiting informed measurement of state-of-the-art LLM capabilities. Here, in response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be an expert-level closed-ended academic benchmark with broad subject coverage. HLE consists of 2,500 questions across dozens of subjects, including mathematics, humanities and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable but cannot be quickly answered by internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a marked gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.",
date = "2026/01/01",
date-added = "2026-01-30 08:32:32 -0500",
date-modified = "2026-01-30 08:54:45 -0500",
doi = "10.1038/s41586-025-09962-4",
id = "Phan2026",
isbn = "1476-4687",
journal = "Nature",
number = "8099",
booktitle = "Nature",
pages = "1139--1146",
title = "A benchmark of expert-level academic questions to assess AI capabilities",
url = "https://doi.org/10.1038/s41586-025-09962-4",
volume = "649",
year = "2026",
bdsk-url-1 = "https://doi.org/10.1038/s41586-025-09962-4"
}

Mike He, Zhendong Ang, Ankush Desai, Aarti Gupta
Proceedings of the 1st ACM SIGPLAN International Workshop on Language Models and Programming Languages, 2025
Project PagePaperCode
@inproceedings{he2025lmpl,
author = "He, Mike and Ang, Zhendong and Desai, Ankush and Gupta, Aarti",
title = "Ranking Formal Specifications using LLMs",
year = "2025",
isbn = "9798400721489",
publisher = "Association for Computing Machinery",
address = "New York, NY, USA",
url = "https://doi.org/10.1145/3759425.3763386",
doi = "10.1145/3759425.3763386",
abstract = "Formal specifications are essential for reasoning about the correctness of complex systems. While recent advances have explored automatically learning such specifications, the challenge of distinguishing meaningful, non-trivial specifications from a vast and noisy pool of learned candidates remains largely open. In this position paper, we present an approach for specification ranking, aimed at identifying the most critical specifications that contribute to overall system correctness. To this end, we develop a four-metric rating framework that quantifies the importance of a specification. Our approach leverages the reasoning capabilities of Large Language Models to rank specifications from a set of automatically learned candidates. We evaluate the proposed method on a set of specifications inferred for 11 open-source and 3 proprietary distributed system benchmarks, demonstrating its effectiveness in ranking critical specifications.",
booktitle = "Proceedings of the 1st ACM SIGPLAN International Workshop on Language Models and Programming Languages",
pages = "51–56",
numpages = "6",
keywords = "Agentic workflows, Ranking specifications",
location = "Singapore, Singapore",
series = "LMPL '25"
}
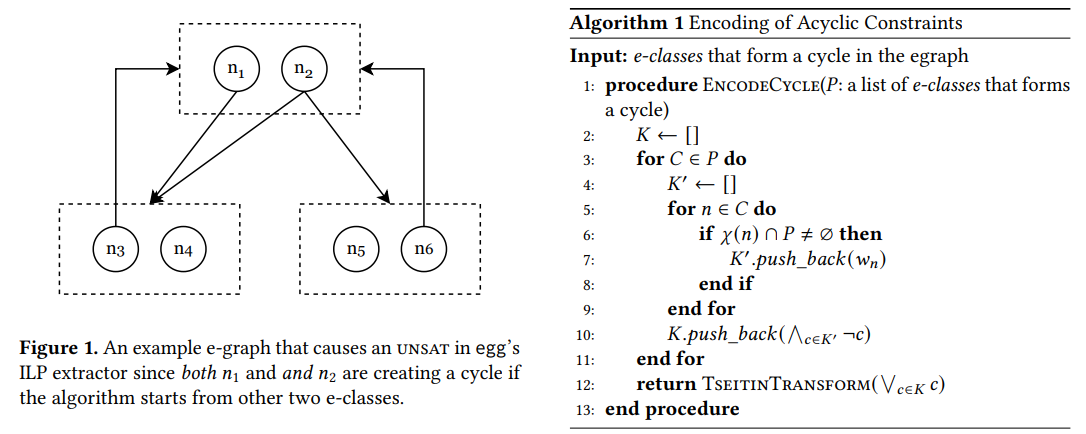
Mike He, Haichen Dong, Sharad Malik, Aarti Gupta
E-Graph Research, Applications, Practices, and Human-factors Symposium (PLDI/EGRAPHS'23), 2023
Project PagePaperCode
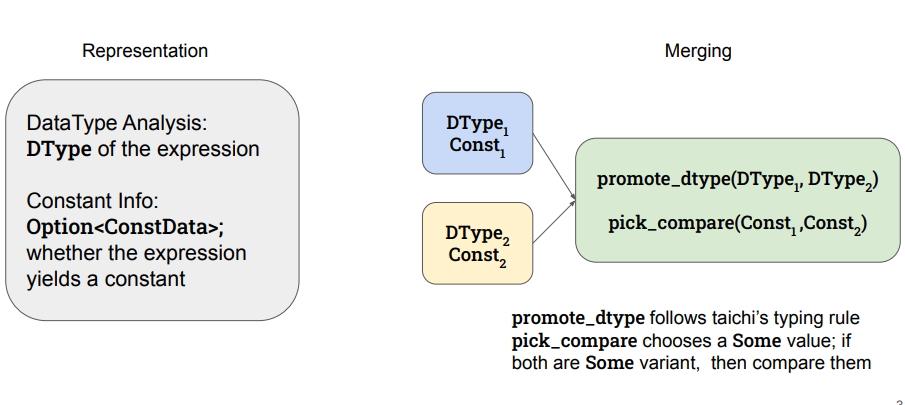
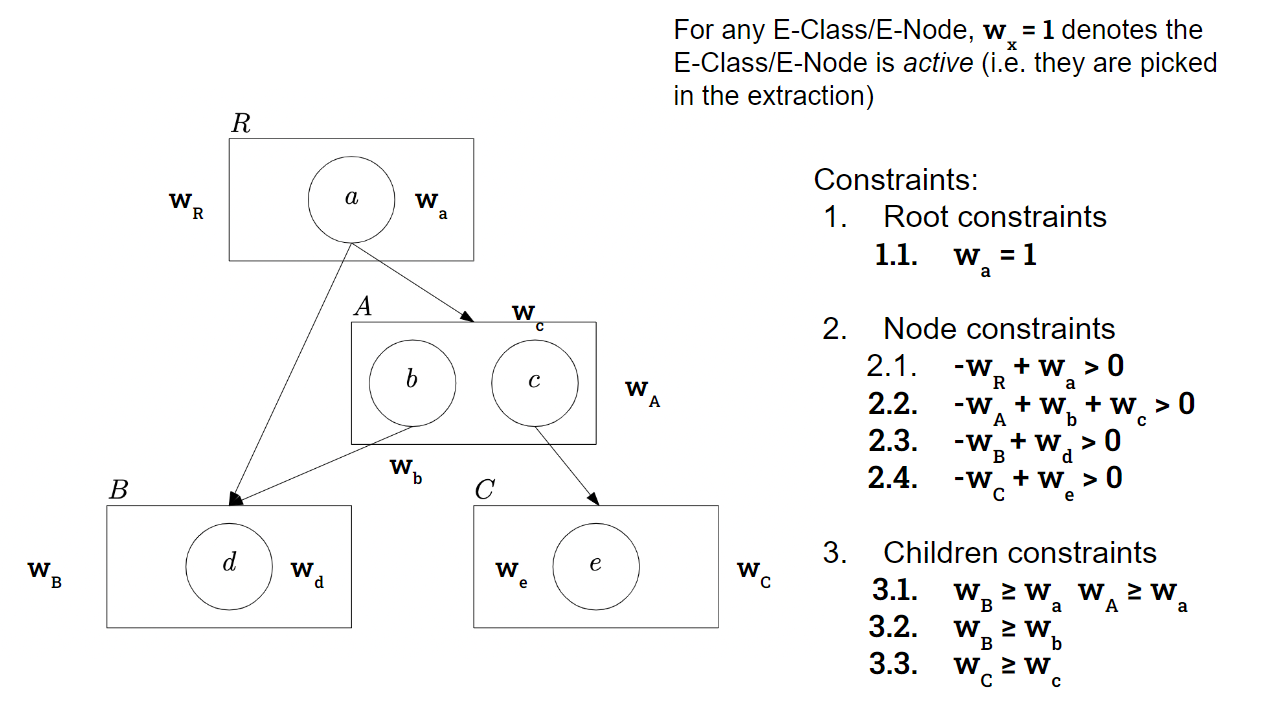
@article{he23extraction,
author = "He, Mike and Dong, Haichen and Malik, Sharad and Gupta, Aarti",
title = "Improving Term Extraction with Acyclic Constraints",
booktitle = "E-Graph Research, Applications, Practices, and Human-factors Symposium (PLDI/EGRAPHS'23)",
year = "2023",
url = ""
}
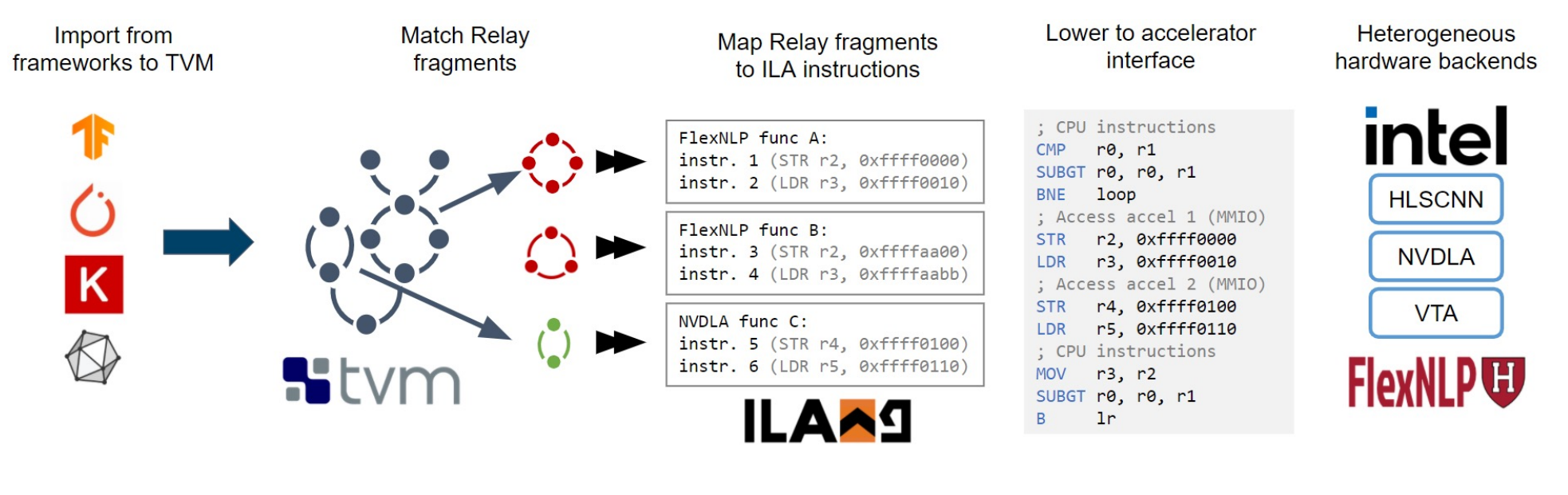
Bo-Yuan Huang*, Steven Lyubomirsky*, Thierry Tambe*, Yi Li, Mike He, Gus Smith, Gu-Yeon Wei, Aarti Gupta, Sharad Malik, Zachary Tatlock
Workshop on Languages, Tools, and Techniques for Accelerator Design (LATTE'21), 2021
Project PagePaperPoster
@article{huang21latte,
author = "Huang*, Bo-Yuan and Lyubomirsky*, Steven and Tambe*, Thierry and Li, Yi and He, Mike and Smith, Gus and Wei, Gu-Yeon and Gupta, Aarti and Malik, Sharad and Tatlock, Zachary",
title = "From DSLs to Accelerator-rich Platform Implementations: Addressing the Mapping Gap",
booktitle = "Workshop on Languages, Tools, and Techniques for Accelerator Design (LATTE'21)",
year = "2021",
url = "https://capra.cs.cornell.edu/latte21/paper/30.pdf"
}
Education

Ph.D. in Computer Science
M.A. in Computer Science
Advisor: Prof. Aarti Gupta Co-Advisor: Prof. Sharad Malik

B.S. in Computer Science
Advisor: Prof. Zachary Tatlock
Experience

Applied Scientist Intern
Mentor: Dr. Siva Somayyajula Boston, MA
Applied Scientist Intern
Mentor: Dr. Ankush Desai Santa Clara, CA
Applied Scientist Intern
Mentor: Dr. Ankush Desai Santa Clara, CA

Formal Verification Research Intern
Mentor: Dr. Zhenkun Yang
Remote and Hillsboro, OR

Research Assistant
Mentor: Dr. Steven Lybomirsky
Seattle, WA
Talks

ICML'26, July 2026
Poster
Georgia Tech - Dependently Typed Talk, April 13, 2026
Slides

Princeton University, December 2023
Slides

Intel Labs, June 2022
Slides
Professional Activities
- Reviewer: NeurIPS, IEEE TMC, AAE@KDD, SciPy
- Artifact Evaluation: POPL, PLDI, MLSys, MICRO
Misc
- I love classical music and enjoy playing the violin. I've been playing the violin for about 20 years. I received the Lv.9 certification issued by the Central Conservatory of Music when I was in middle school. You can find some of my recordings here. Some video recordings are available @ Bilibili (the website is in Chinese).
- I was a part-time translator / proofreading editor in Gawr Gura's Chinese fansub team. Gura, now graduated, was a virtual streamer at YouTube affiliated with Hololive Production (EN).
- My Erdős number is 3: Mike He [3] → Sanjeev Arora [2] → László Babai [1] → Paul Erdős [0]
Friends and Colleagues (by alphabetical order of last names)
-
NUSZhendong Anghttps://ang9876.github.io/
-
PrincetonSanjeev Arorahttps://www.cs.princeton.edu/~arora/
-
UPennOsbert Bastanihttps://obastani.github.io/
-
Jennifer Brennanhttps://jenniferbrennan.github.io/
-
StanfordVishal Canumallahttps://vcanumalla.github.io/
-
CMUTianqi Chenhttps://tqchen.com/
-
PrincetonYinwei Daihttps://yinwei-dai.com/
-
SnowflakeAnkush Desaihttps://ankushdesai.github.io/
-
BlackSesameHaichen Donghttps://haichendong.com/
- Utah
-
UC BerkeleyAltan Haanhttps://altanh.com/
-
IntelBo-yuan Huanghttps://boyuanhuang.com/
- Princeton
-
UtahMarisa Kirisamehttps://marisa.moe/
- Meta
-
ETH ZurichZenan Lihttps://lizn-zn.github.io/
- UIUC
-
UTorontoZhaoyu Lihttps://www.zhaoyu-li.com/
-
NVIDIASteven Lyubomirskyhttps://slyubomirsky.github.io/
-
UPennMarcus Minhttps://marcusm117.github.io/
-
AWSFederico Mora Rochahttps://federico.morarocha.ca/
-
NVIDIAJared Roeschhttps://jroesch.github.io/
-
UTorontoXujie Sihttps://www.cs.toronto.edu/~six/
-
ChipstackGus Smithhttps://justg.us/
-
ETH ZurichZhendong Suhttps://people.inf.ethz.ch/suz/
-
StanfordThierry Tambehttps://thierrytambe.com/
-
PrincetonShange Tanghttps://shangetang.github.io/
-
UWZachary Tatlockhttps://ztatlock.net/
-
UIUCVenugopal V. Veeravallihttps://vvv.ece.illinois.edu/
-
MicrosoftShaoqi Wanghttps://www.linkedin.com/in/shaoqiw/
-
HarvardGu-Yeon Weihttps://seas.harvard.edu/person/gu-yeon-wei
-
MBZUAIHobart Yanghttps://discover304.top/
-
MiroMindKaiyu Yanghttps://yangky11.github.io/
-
PrincetonZiran Yanghttps://ziranyang0.github.io/
-
OpenAIGuanghao Yehttps://yeguanghao.xyz/
-
UPennZixuan Yihttps://zixy17.github.io/
-
CMUYinsen (Tesla) Zhanghttps://ice1000.org/
-
UWYihong Zhanghttps://effect.systems/
-
USCMuru Zhanghttps://nanami18.github.io/
-
PrincetonHaoyu Zhaohttps://hyzhao.me/
- Princeton
-
PurdueZhe Zhouhttps://zhezhouzz.github.io/
-
USCChenyu Zhouhttps://self.shiroha.info/
-
UofRYifan Zhuhttps://www.cs.rochester.edu/~yzhu104/
Visitors are welcomed!
This website is adapted from a template generously provided by Michael Niemeyer. The Logo of this website is designed by my friend, Melina.